
Xiaofeng Gao
1120 Enterprise WaySunnyvale, CA, 94089 Email: xfgao at ucla dot edu
[Google Scholar] [GitHub]
I'm an Applied Scientist at Amazon. My research lies in the intersection of Robotics, Computer Vision, Machine Learning and Cognitive Science, with a focus on developing cognitively inspired cooperative agents. I received my PhD in Statistics from University of California, Los Angeles under the supervision of Prof. Song-Chun Zhu.
During my PhD, I also worked closely with Prof. Hongjing Lu (UCLA), Prof. Gaurav Sukhatme (USC & Amazon) and Prof. Tianmin Shu (JHU). Before that, I obtained a bachelor degree of Electronic Engineering at Fudan University.
04/2024: We are hosting the ARNOLD challenge as a part of CVPR 2024 Embodied AI Workshop. Welcome to participate!
02/2024: Groundhog is accepted by CVPR.
09/2023: Alexa Arena is accepted by NeurIPS 2023 Datasets and Benchmarks track.
08/2023: LEMMA is accepted by RA-L.
07/2023: ARNOLD is accepted by ICCV 2023.
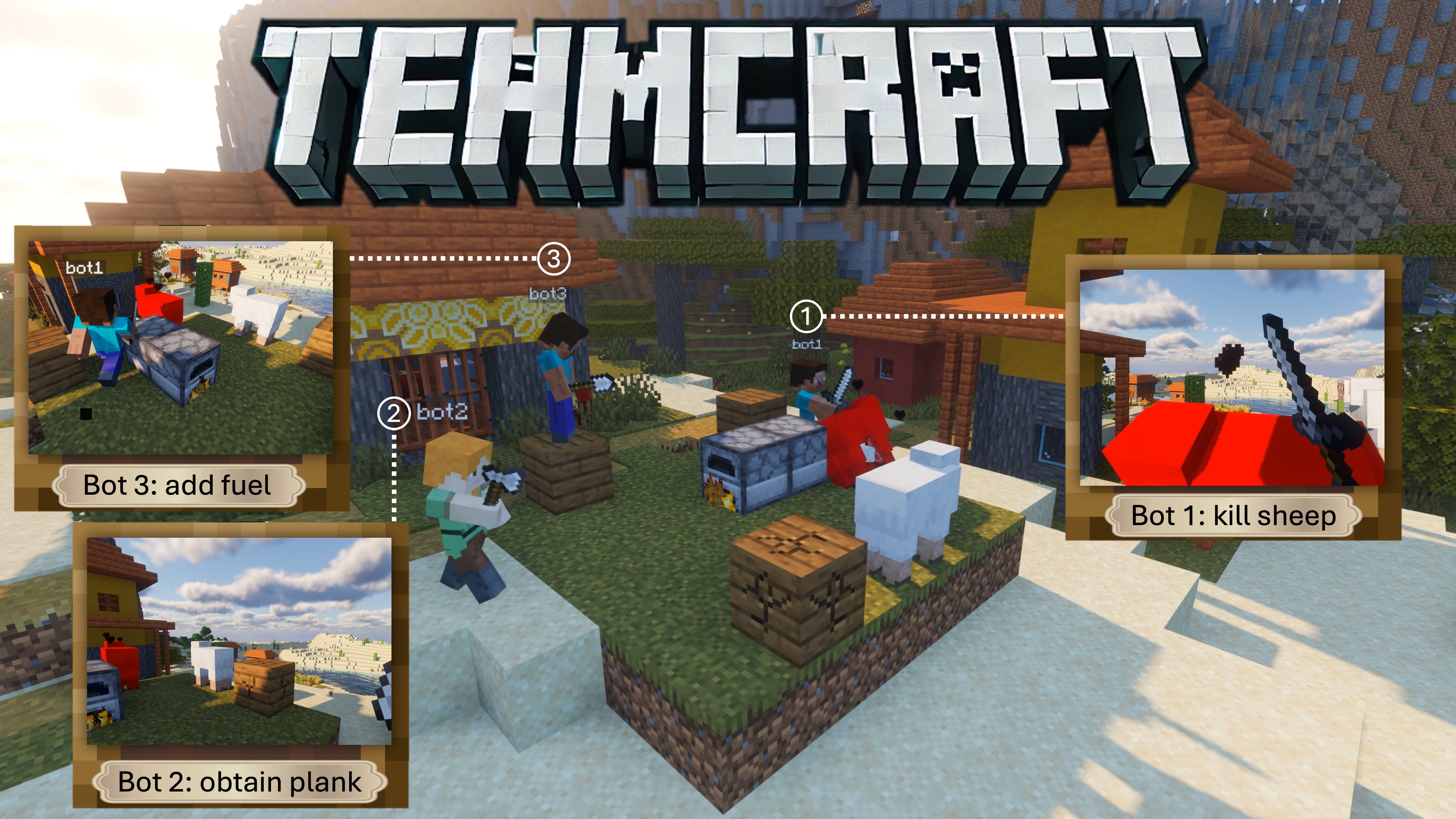
@article{long2024teamcraft,
title={TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft},
author={Long, Qian and Li, Zhi and Gong, Ran and Wu, Ying Nian and Terzopoulos, Demetri and Gao, Xiaofeng},
journal={arXiv preprint arXiv:2412.05255},
year={2024}
}

@InProceedings{li2024mastering,
title = {Mastering Robot Manipulation with Multimodal Prompts through Pretraining and Multi-task Fine-tuning},
author = {Li, Jiachen and Gao, Qiaozi and Johnston, Michael and Gao, Xiaofeng and He, Xuehai and Shi, Hangjie and Shakiah, Suhaila and Ghanadan, Reza and Wang, William Yang},
booktitle = {Proceedings of the 41st International Conference on Machine Learning},
pages = {27822--27845},
year = {2024},
editor = {Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix},
volume = {235},
series = {Proceedings of Machine Learning Research},
month = {21--27 Jul},
publisher = {PMLR},
pdf = {https://raw.githubusercontent.com/mlresearch/v235/main/assets/li24x/li24x.pdf},
url = {https://proceedings.mlr.press/v235/li24x.html},
}

@InProceedings{zhang2024groundhog,
author = {Zhang, Yichi and Ma, Ziqiao and Gao, Xiaofeng and Shakiah, Suhaila and Gao, Qiaozi and Chai, Joyce},
title = {GROUNDHOG: Grounding Large Language Models to Holistic Segmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {14227-14238}
}

@ARTICLE{gong2023lemma,
author={Gong, Ran and Gao, Xiaofeng and Gao, Qiaozi and Shakiah, Suhaila and Thattai, Govind and Sukhatme, Gaurav S.},
journal={IEEE Robotics and Automation Letters},
title={LEMMA: Learning Language-Conditioned Multi-Robot Manipulation},
year={2023},
volume={8},
number={10},
pages={6835-6842},
keywords={Task analysis;Robots;Robot kinematics;Planning;Benchmark testing;Collaboration;Multitasking;Multi-robot systems;Data Sets for Robot Learning;Natural Dialog for HRI;Multi-Robot Systems},
doi={10.1109/LRA.2023.3313058}}
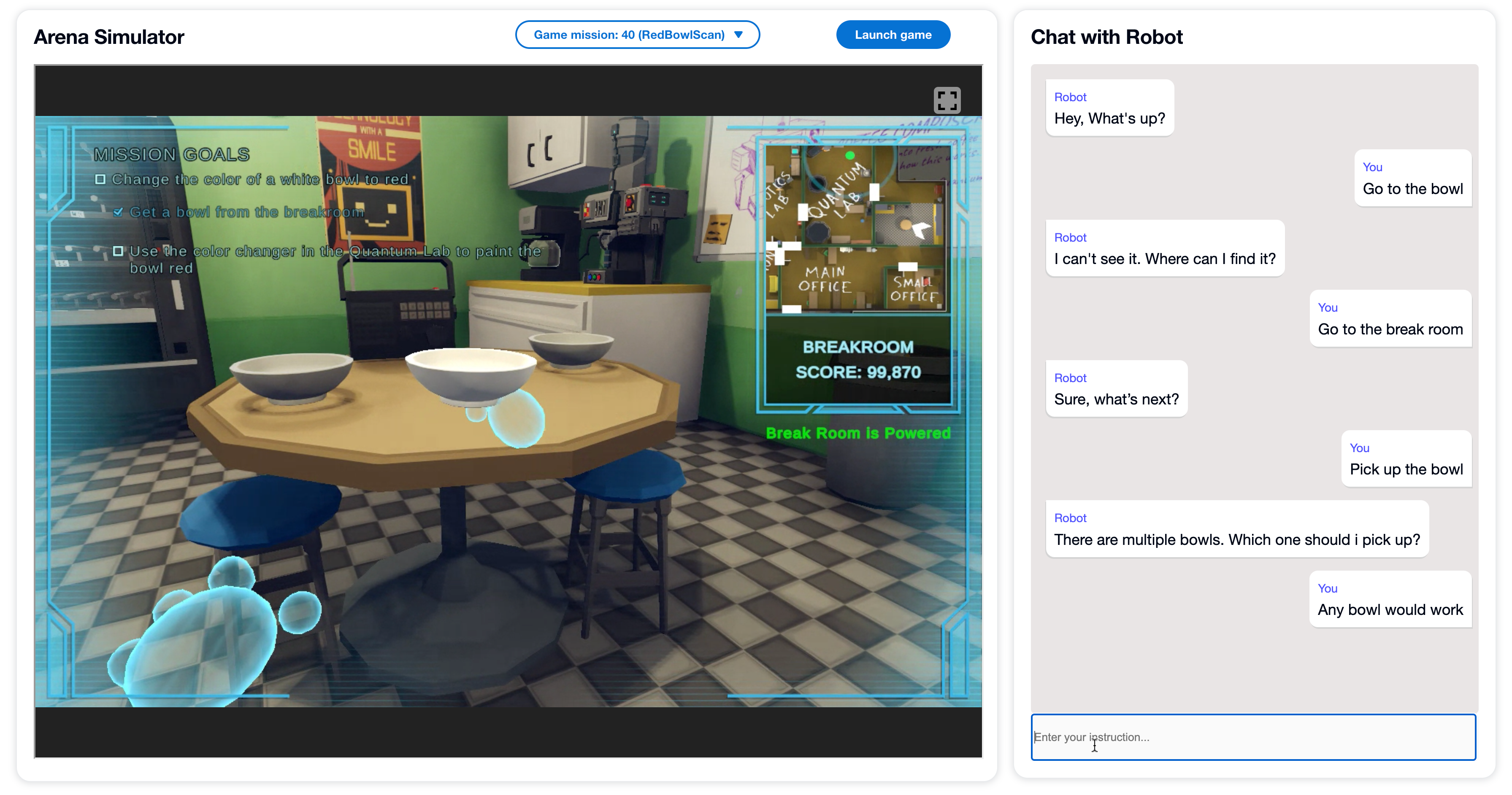
Qiaozi Gao*, Govind Thattai*, Suhaila Shakiah*, Xiaofeng Gao*, Shreyas Pansare, Vasu Sharma, Gaurav S. Sukhatme, Hangjie Shi, Bofei Yang, Desheng Zhang, Lucy Hu, Karthika Arumugam, Shui Hu, Matthew Wen, Dinakar Venkateswar Guthy, Shunan Cadence Chung, Rohan Khanna, Osman Ipek, Leslie Ball, Kate Bland, Heather Rocker, Michael Johnston, Reza Ghanadan, Dilek Hakkani-Tur, Prem Natarajan
Conference on Neural Information Processing Systems (NeurIPS), 2023
@inproceedings{gao2023alexa,
author = {Gao, Qiaozi and Thattai, Govind and Shakiah, Suhaila and Gao, Xiaofeng and Pansare, Shreyas and Sharma, Vasu and Sukhatme, Gaurav and Shi, Hangjie and Yang, Bofei and Zhang, Desheng and Hu, Lucy and Arumugam, Karthika and Hu, Shui and Wen, Matthew and Guthy, Dinakar and Chung, Shunan and Khanna, Rohan and Ipek, Osman and Ball, Leslie and Bland, Kate and Rocker, Heather and Johnston, Michael and Ghanadan, Reza and Hakkani-Tur, Dilek and Natarajan, Prem},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Oh and T. Naumann and A. Globerson and K. Saenko and M. Hardt and S. Levine},
pages = {19170--19194},
publisher = {Curran Associates, Inc.},
title = {Alexa Arena: A User-Centric Interactive Platform for Embodied AI},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/3d0758f0b95e19abc68c1c8070d36510-Paper-Datasets_and_Benchmarks.pdf},
volume = {36},
year = {2023}
}

Ran Gong*,
Jiangyong Huang*,
Yizhou Zhao,
Haoran Geng,
Xiaofeng Gao,
Qingyang Wu,
Wensi Ai,
Ziheng Zhou,
Demetri Terzopoulos,
Song-Chun Zhu,
Baoxiong Jia,
Siyuan Huang
International Conference on Computer Vision (ICCV), 2023
@InProceedings{gong2023arnold,
author = {Gong, Ran and Huang, Jiangyong and Zhao, Yizhou and Geng, Haoran and Gao, Xiaofeng and Wu, Qingyang and Ai, Wensi and Zhou, Ziheng and Terzopoulos, Demetri and Zhu, Song-Chun and Jia, Baoxiong and Huang, Siyuan},
title = {ARNOLD: A Benchmark for Language-Grounded Task Learning with Continuous States in Realistic 3D Scenes},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {20483-20495}
}

Luyao Yuan*,
Xiaofeng Gao*,
Zilong Zheng*,
Mark Edmonds,
Ying Nian Wu,
Federico Rossano,
Hongjing Lu,
Yixin Zhu,
Song-Chun Zhu
Science Robotics, 2022
@article{yuan2022in,
title={In situ bidirectional human-robot value alignment},
author={Yuan, Luyao and Gao, Xiaofeng and Zheng, Zilong and Edmonds, Mark and Wu, Ying Nian and Rossano, Federico and Lu, Hongjing and Zhu, Yixin and Zhu, Song-Chun},
journal={Science Robotics},
volume={7},
number={68},
year={2022},
publisher={Science Robotics}
}
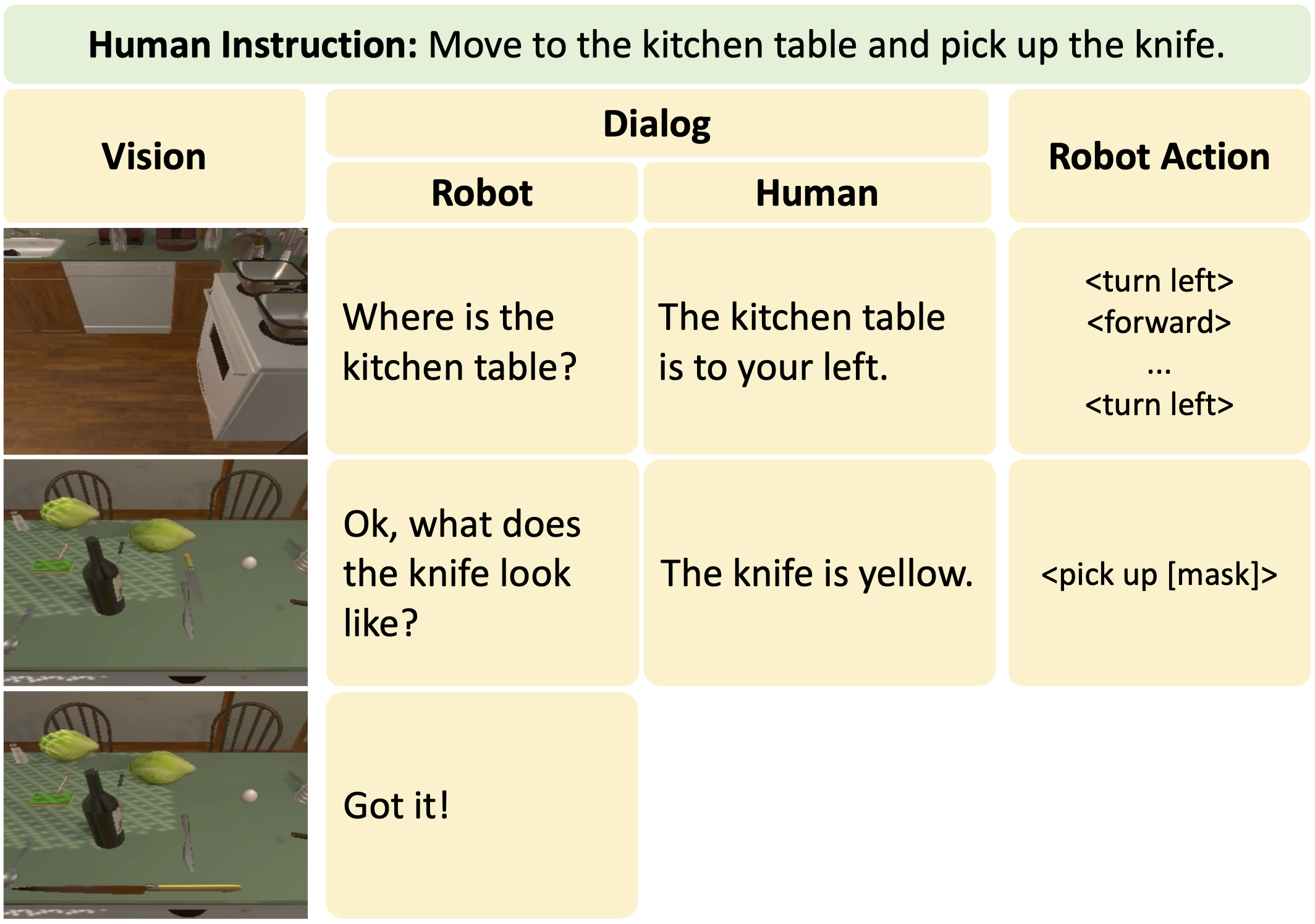
@article{gao2022dialfred,
title={DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following},
author={Gao, Xiaofeng and Gao, Qiaozi and Gong, Ran and Lin, Kaixiang and Thattai, Govind and Sukhatme, Gaurav S.},
journal={IEEE Robotics and Automation Letters},
year={2022},
volume={7},
number={4},
pages={10049-10056},
doi={10.1109/LRA.2022.3193254}
}

@inproceedings{gao2022effects,
title={Effects of Augmented-Reality-Based Assisting Interfaces on Drivers' Object-wise Situational Awareness in Highly Autonomous Vehicles},
author={Gao, Xiaofeng and Wu, Xingwei and Ho, Samson and Misu, Teruhisa and Akash, Kumar},
booktitle={2022 IEEE Intelligent Vehicles Symposium (IV)},
pages={563-572},
year={2022},
organization={IEEE}
}

Xiaofeng Gao,
Luyao Yuan,
Tianmin Shu,
Hongjing Lu,
Song-Chun Zhu
IEEE Robotics and Automation Letters (RA-L), 2022
@article{gao2022show,
title={Show Me What You Can Do: Capability Calibration on Reachable Workspace for Human-Robot Collaboration},
author={Gao, Xiaofeng and Yuan, Luyao and Shu, Tianmin and Lu, Hongjing and Zhu, Song-Chun},
journal={IEEE Robotics and Automation Letters},
volume={7},
number={2},
pages={2644--2651},
year={2022},
publisher={IEEE}
}
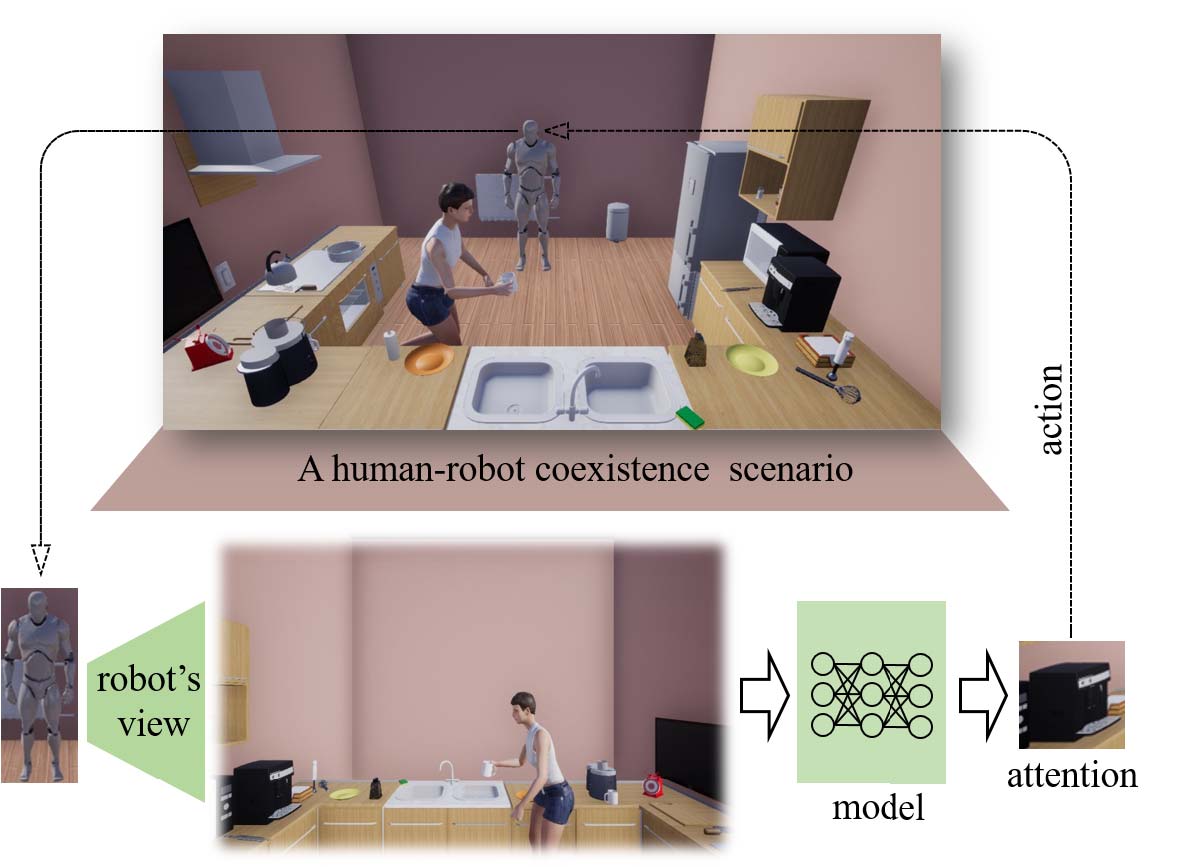
Zhixiong Nan,
Jingjing Jiang,
Xiaofeng Gao,
Sanping Zhou,
Weiliang Zuo,
Ping Wei,
Nanning Zheng
IEEE Transactions on Image Processing (TIP), 2021
@article{nan2021predicting,
title={Predicting Task-Driven Attention via Integrating Bottom-Up Stimulus and Top-Down Guidance},
author={Nan, Zhixiong and Jiang, Jingjing and Gao, Xiaofeng and Zhou, Sanping and Zuo, Weiliang and Wei, Ping and Zheng, Nanning},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={8293--8305},
year={2021},
publisher={IEEE}
}
Xiaofeng Gao*,
Ran Gong*,
Yizhou Zhao,
Shu Wang,
Tianmin Shu,
Song-Chun Zhu
IEEE International Conference on Robot & Human Interactive Communication (RO-MAN), 2020
@inproceedings{gao2020joint,
title={Joint Mind Modeling for Explanation Generation in Complex Human-Robot Collaborative Tasks},
author={Gao, Xiaofeng and Gong, Ran and Zhao, Yizhou and Wang, Shu and Shu, Tianmin and Zhu, Song-Chun},
booktitle={2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)},
pages={1119--1126},
year={2020},
organization={IEEE}
}

Xiaofeng Gao,
Ran Gong,
Tianmin Shu,
Xu Xie,
Shu Wang,
Song-Chun Zhu
ICML workshop on Reinforcement Learning for Real Life, 2019
@article{gao2019vrkitchen,
title={Vrkitchen: an interactive 3d virtual environment for task-oriented learning},
author={Gao, Xiaofeng and Gong, Ran and Shu, Tianmin and Xie, Xu and Wang, Shu and Zhu, Song-Chun},
journal={arXiv preprint arXiv:1903.05757},
year={2019}
}

Tianmin Shu,
Xiaofeng Gao,
Michael S. Ryoo,
Song-Chun Zhu
IEEE International Conference on Robotics and Automation (ICRA), 2017